


【折腾笔记】利用AI大模型构建本地知识库
本文最后更新于 2025-07-23,文章可能存在过时内容,如有过时内容欢迎留言或者联系我进行反馈。
前言
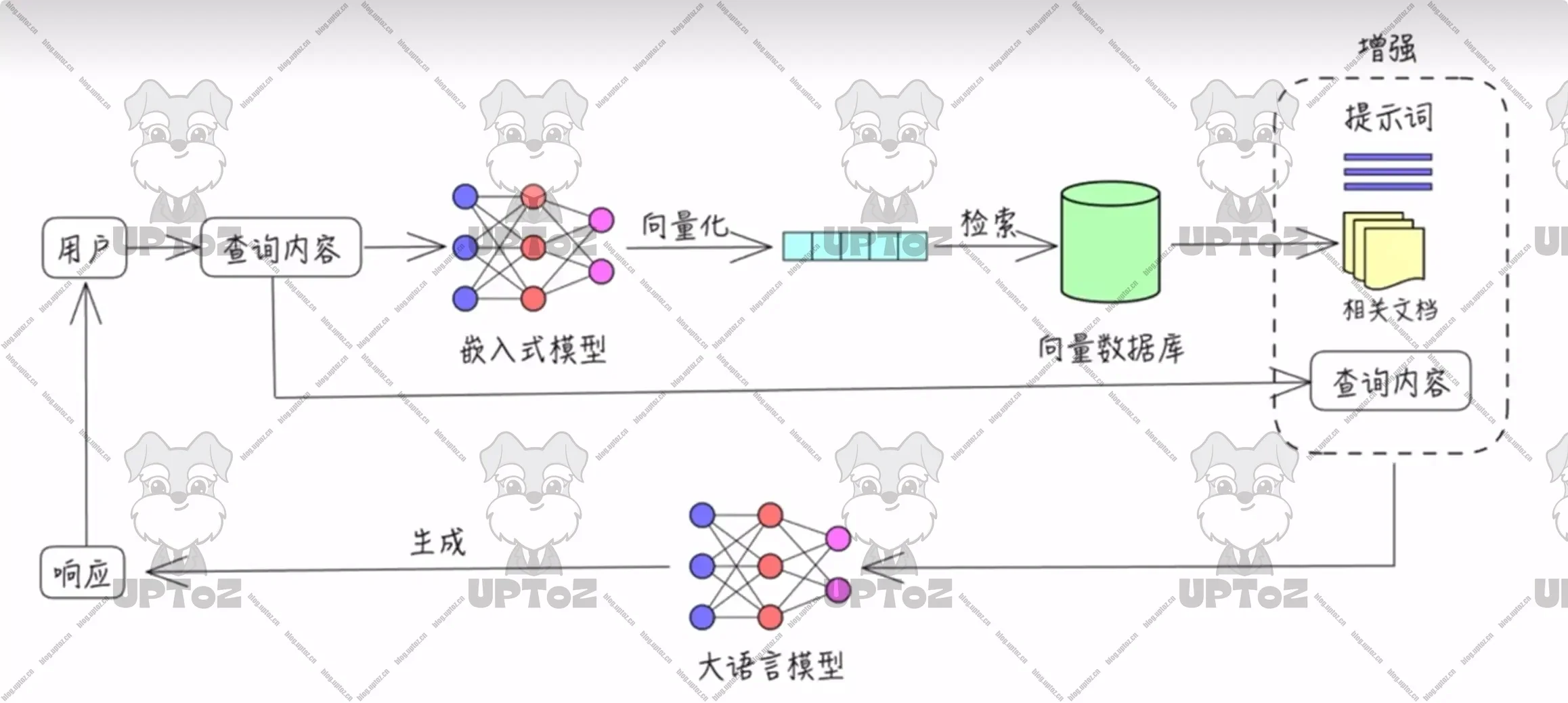
相比传统的知识库,AI知识库具有更高的智能化程度。它不仅能够理解用户的查询意图,还能根据用户的历史行为和偏好进行个性化推荐。此外,AI大模型知识库还具备知识推理、问答生成等高级功能,能够为用户提供更加智能、个性化的知识服务。这使得AI大模型知识库在教育、医疗、金融、客服等多个领域具有广泛的应用前景。
云端AI知识库可能涉及敏感数据泄露风险,因此企业更倾向本地化部署以保障数据安全。为帮助用户实现这一目标,本教程将基于Windows系统,通过Ollama(本地模型管理) + DeepSeek(开源中文模型) + AnythingLLM(私有知识库框架) 的组合方案,逐步演示如何构建安全可控的本地AI知识库。
简介
Ollama(本地模型管理)
Ollama 是一个开源的本地大语言模型运行框架。
基本概念
核心功能:Ollama 专注于在本地机器上便捷部署和运行大型语言模型(LLM),支持多种操作系统,包括 macOS、Windows、Linux 以及通过 Docker 容器运行。
主要特点:它提供对模型量化的支持,可以显著降低显存要求,使得在普通家用计算机上运行大型模型成为可能。
主要特点
多种预训练语言模型支持:Ollama 提供了多种开箱即用的预训练模型,包括常见的 GPT、BERT 等大型语言模型,用户可以轻松加载并使用这些模型进行文本生成、情感分析、问答等任务。
易于集成和使用:Ollama 提供了命令行工具(CLI)和 Python SDK,简化了与其他项目和服务的集成,开发者无需担心复杂的依赖或配置,可以快速将 Ollama 集成到现有的应用中。
本地部署与离线使用:Ollama 允许开发者在本地计算环境中运行模型,这意味着可以脱离对外部服务器的依赖,保证数据隐私,并且对于高并发的请求,离线部署能提供更低的延迟和更高的可控性。
支持模型微调与自定义:用户不仅可以使用 Ollama 提供的预训练模型,还可以在此基础上进行模型微调,根据自己的特定需求,开发者可以使用自己收集的数据对模型进行再训练,从而优化模型的性能和准确度。
性能优化:Ollama 关注性能,提供了高效的推理机制,支持批量处理,能够有效管理内存和计算资源,这让它在处理大规模数据时依然保持高效。
跨平台支持:Ollama 支持在多个操作系统上运行,包括 Windows、macOS 和 Linux,这样无论是开发者在本地环境调试,还是企业在生产环境部署,都能得到一致的体验。
开放源码与社区支持:Ollama 是一个开源项目,这意味着开发者可以查看源代码,进行修改和优化,也可以参与到项目的贡献中,此外,Ollama 有一个活跃的社区,开发者可以从中获取帮助并与其他人交流经验。
功能
本地模型管理:Ollama 支持从官方模型库或自定义模型库拉取预训练模型,并在本地保存和加载,它支持各种流行的模型格式(如 ONNX、PyTorch、TensorFlow)。
高效推理:通过 GPU/CPU 的加速,Ollama 提供高效的模型推理,适合本地化应用或需要控制数据隐私的场景。
多种接口访问:Ollama 支持命令行(CLI)、HTTP 接口访问推理服务,并通过 OpenAI 客户端实现更广泛的集成。
环境变量配置:通过灵活的环境变量,用户可以自定义推理设备(GPU/CPU)、缓存路径、并发数、日志级别等。
DeepSeek(开源中文模型)
DeepSeek 是一款开源的大语言模型。
核心优势
智能化:DeepSeek 能够理解复杂的问题,并提供精准的解决方案。它通过深度学习和自然语言处理技术,能够理解用户的需求并提供个性化的建议。
多功能性:DeepSeek 在多个领域都有广泛的应用,包括学习、工作和生活。它可以用作学习助手、编程助手、写作助手、生活助手和翻译助手等,满足用户在不同场景下的需求。
易用性:DeepSeek 通过自然语言交互,用户无需学习复杂的操作即可与模型进行对话。这种交互方式使得用户能够轻松地获取所需的信息和服务。
低成本:DeepSeek 的训练和推理成本较低,打破了传统 N 卡垄断,降低了大模型的使用门槛。这使得更多的企业和个人能够使用高性能的 AI 服务。
高效率:DeepSeek 在推理能力和响应速度上表现出色,能够快速处理复杂的查询和任务,提供准确的答案和解决方案。
开源生态:DeepSeek 采用了开源策略,吸引了大量开发者和研究人员的参与,推动了 AI 技术的发展和应用。
技术特点
深度学习:DeepSeek 通过大量的数据训练,学会了如何理解和处理复杂的问题,提供个性化的建议和解决方案。
自然语言处理(NLP):DeepSeek 能够理解人类的语言,无论是中文、英文还是其他语言,支持自然方式的对话。
知识图谱:DeepSeek 存储了大量的结构化知识,能够快速找到相关信息,提供精准的答案。
混合专家模型(MoE):DeepSeek 采用了 MoE 框架,通过训练多个专家模型,并根据输入数据的特征动态选择最合适的专家模型进行处理,从而实现对复杂任务的高效处理。
多头潜在注意力机制(MLA):DeepSeek 的 MLA 技术显著降低了模型推理成本,通过减少对 KV 矩阵的重复计算,提高了模型的运行效率。
大规模强化学习:DeepSeek 通过大规模强化学习技术,增强了模型的推理能力和泛化能力,能够在多个领域中表现出色。
AnythingLLM(私有知识库框架)
AnythingLLM 是一个全栈应用程序,允许用户使用商业现成的 LLM(大语言模型)或流行的开源 LLM 以及向量数据库解决方案,构建一个无需妥协的本地 ChatGPT。用户可以通过它与提供给它的任何文档进行智能交流,新颖的设计使得用户能够选择想要使用的 LLM 或向量数据库,并支持多用户管理和权限设置。
主要特点
多用户支持和权限管理:允许多个用户同时使用,并可设置不同的权限。
支持多种文档类型:包括 PDF、TXT、DOCX 等。
简易的文档管理界面:通过用户界面管理向量数据库中的文档。
两种聊天模式:对话模式保留之前的问题和回答,查询模式则是简单的针对文档的问答。
聊天中的引用标注:链接到原始文档源和文本。
简单的技术栈:便于快速迭代。
100% 云部署就绪:适合云部署。
“自带 LLM”模式:可以选择使用商业或开源的 LLM。
高效的成本节约措施:对于大型文档,只需嵌入一次,比其他文档聊天机器人解决方案节省 90% 的成本。
完整的开发者 API:支持自定义集成。
功能
自定义 AI 代理:用户可以根据需求创建自己的 AI 代理,使应用更具个性化。
支持多模态:不仅支持闭源 LLM,还兼容开源 LLM,拓展了应用的灵活性。
工作区内的代理:支持在工作区内浏览网页、运行代码等操作。
自定义可嵌入聊天小部件:可以嵌入到用户的网站。
部署
前往 Ollama 官方网站(https://ollama.com/download)下载安装包。
直接通过安装包安装Ollama会直接安装在C盘,如果需要自定义安装路径,需要通过命令行指定安装路径,启动安装程序,点击 Install 后,Ollama 就会安装到指定的目录了。
OllamaSetup.exe /DIR=E:\MySoftware\Ollama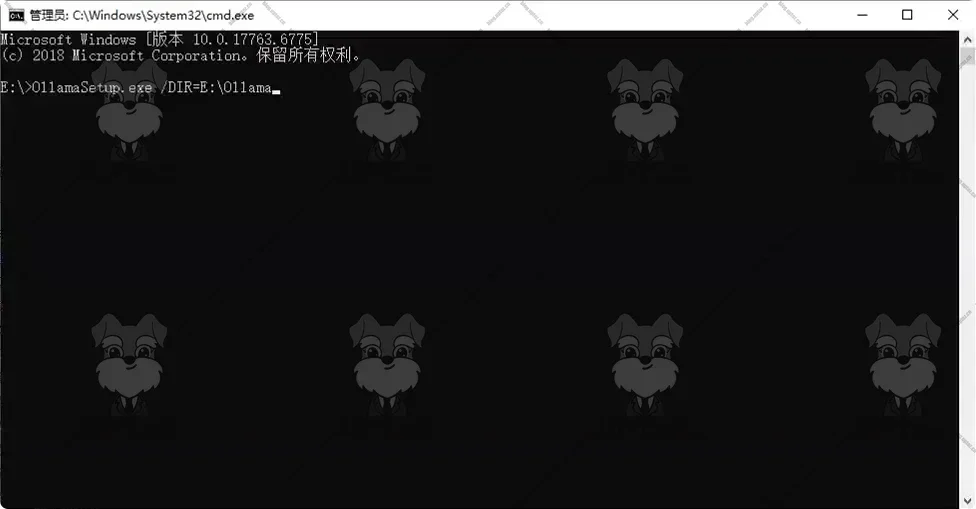
打开一个新的命令行,输入
ollama回车执行,如果返回以下内容,则表示安装成功。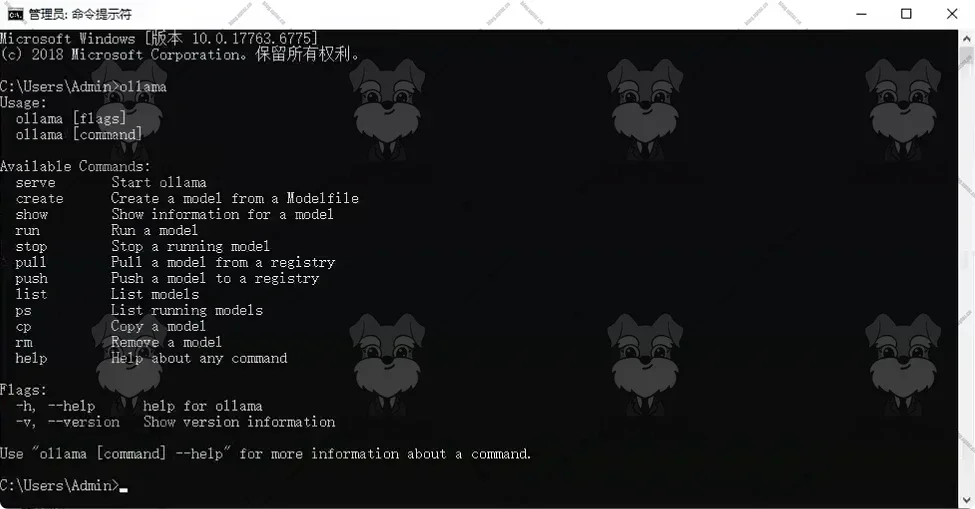
在浏览器中输入
127.0.0.1:11434,显示Ollama is running表示Ollama已经成功运行。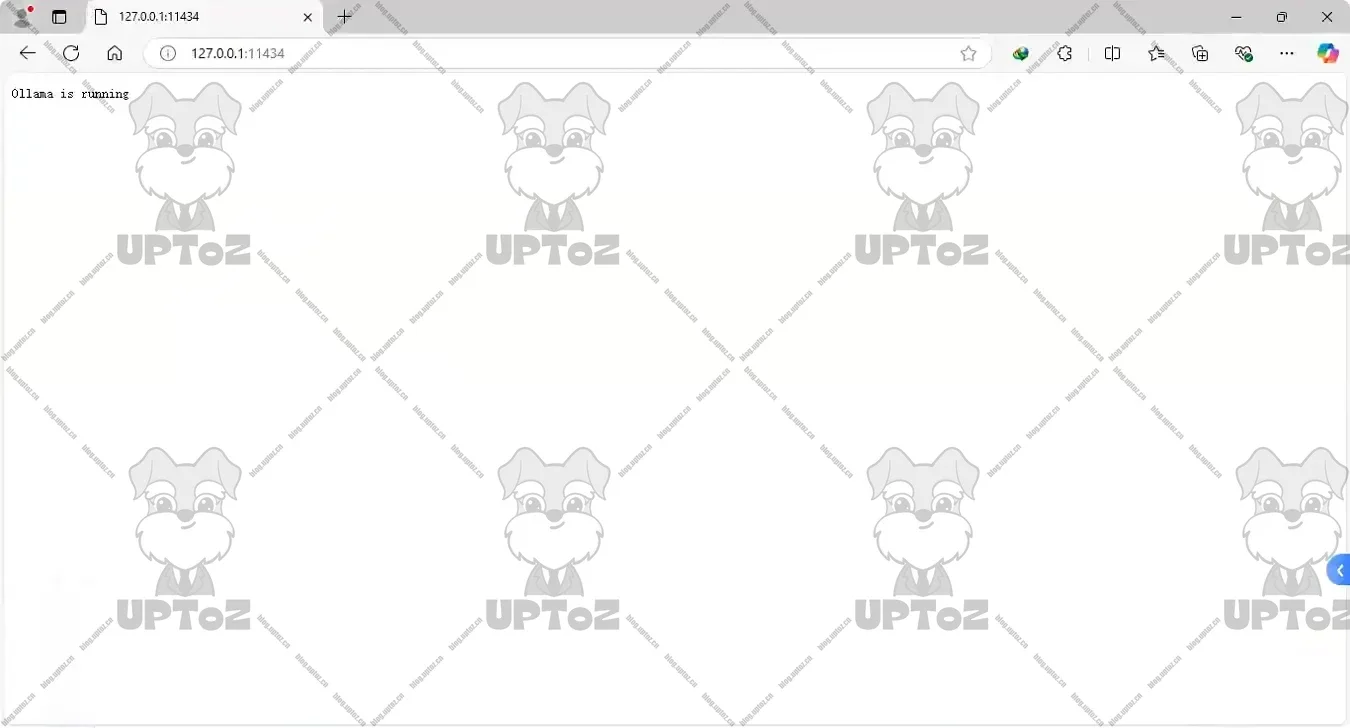
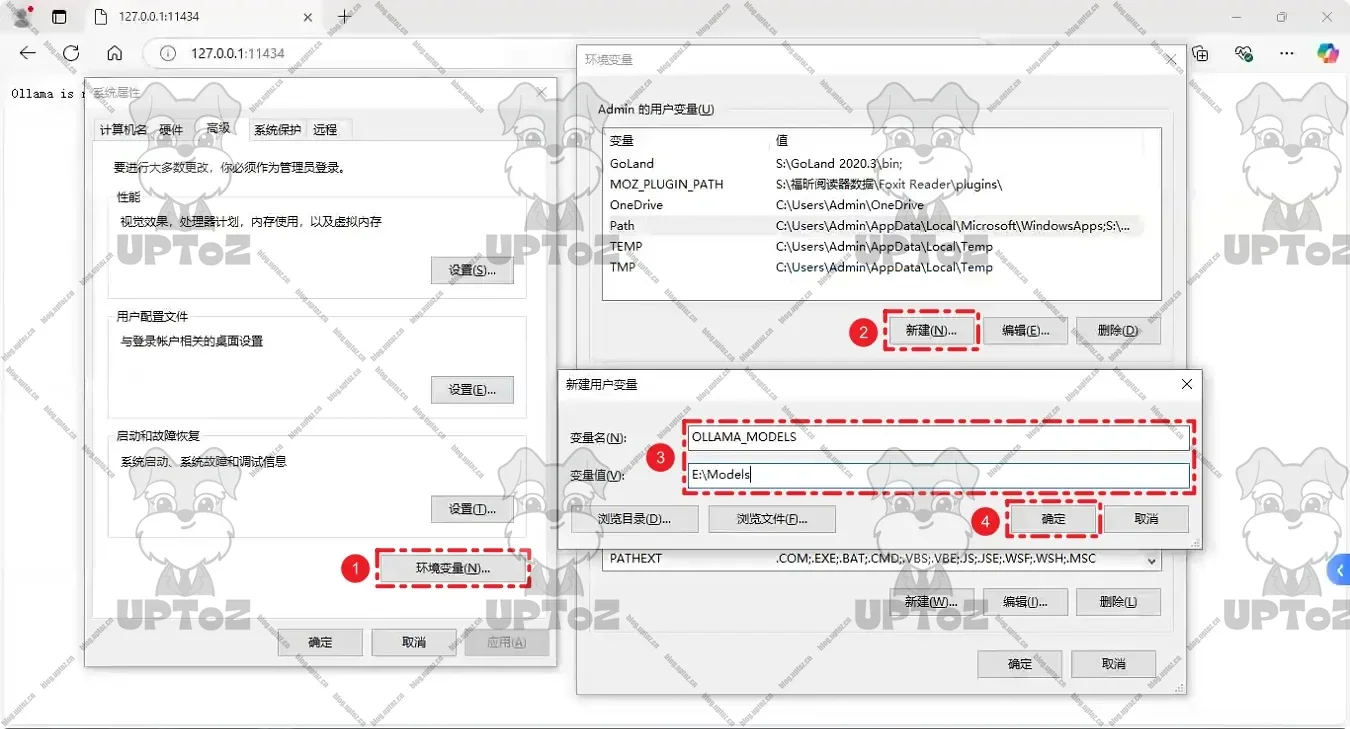
更改模型存储位置。大模型资源包默认下载到 C 盘,可以手动创建大模型存储目录,然后在用户账户中设置环境变量
OLLAMA_MODELS,将其设置为希望存储模型的路径。需要重启Ollama才能生效!
拉取模型到本地。在命令行输入
ollama pull deepseek-r1:32b。根据本机配置和业务需求进行选择模型参数。
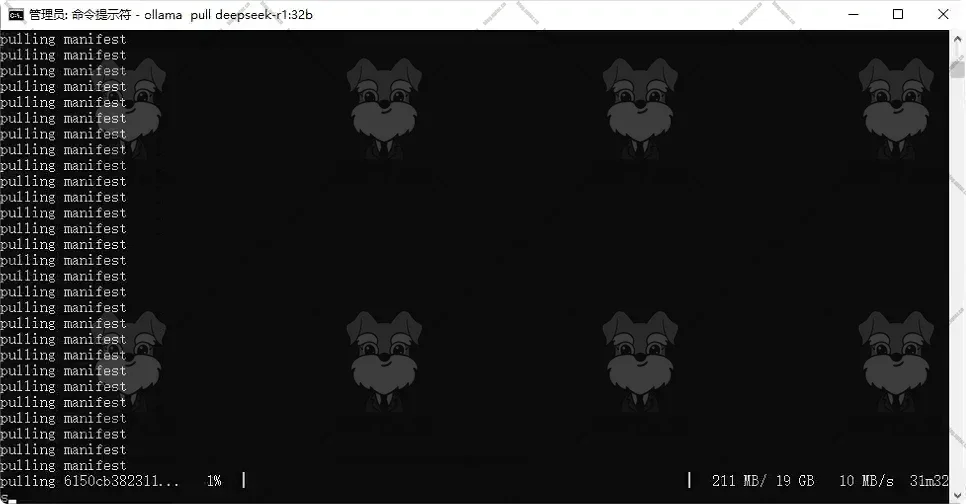
等待模型拉取到本地。
拉取嵌入模型
nomic-embed-text。ollama pull nomic-embed-text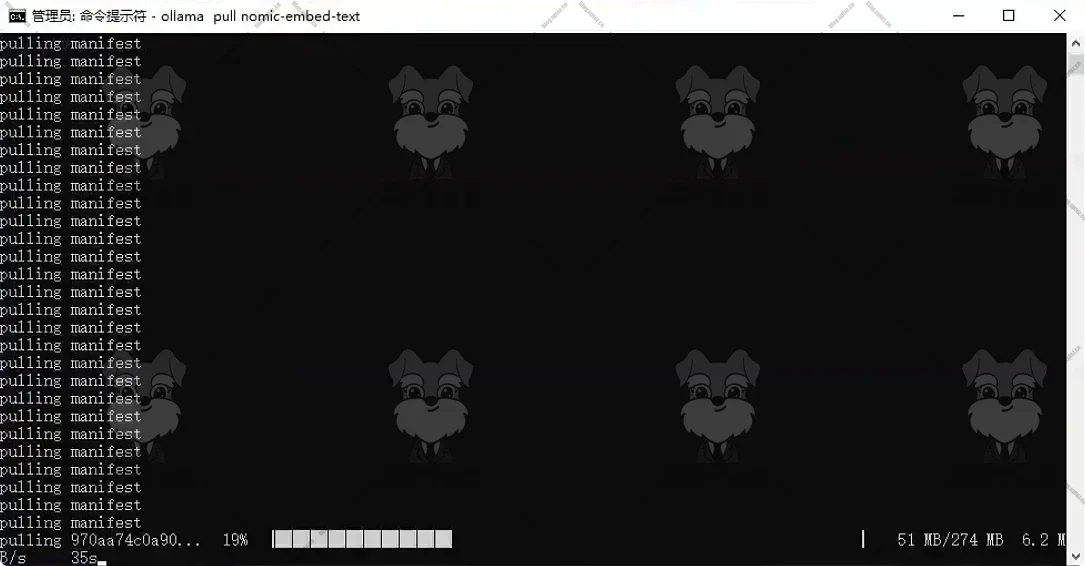
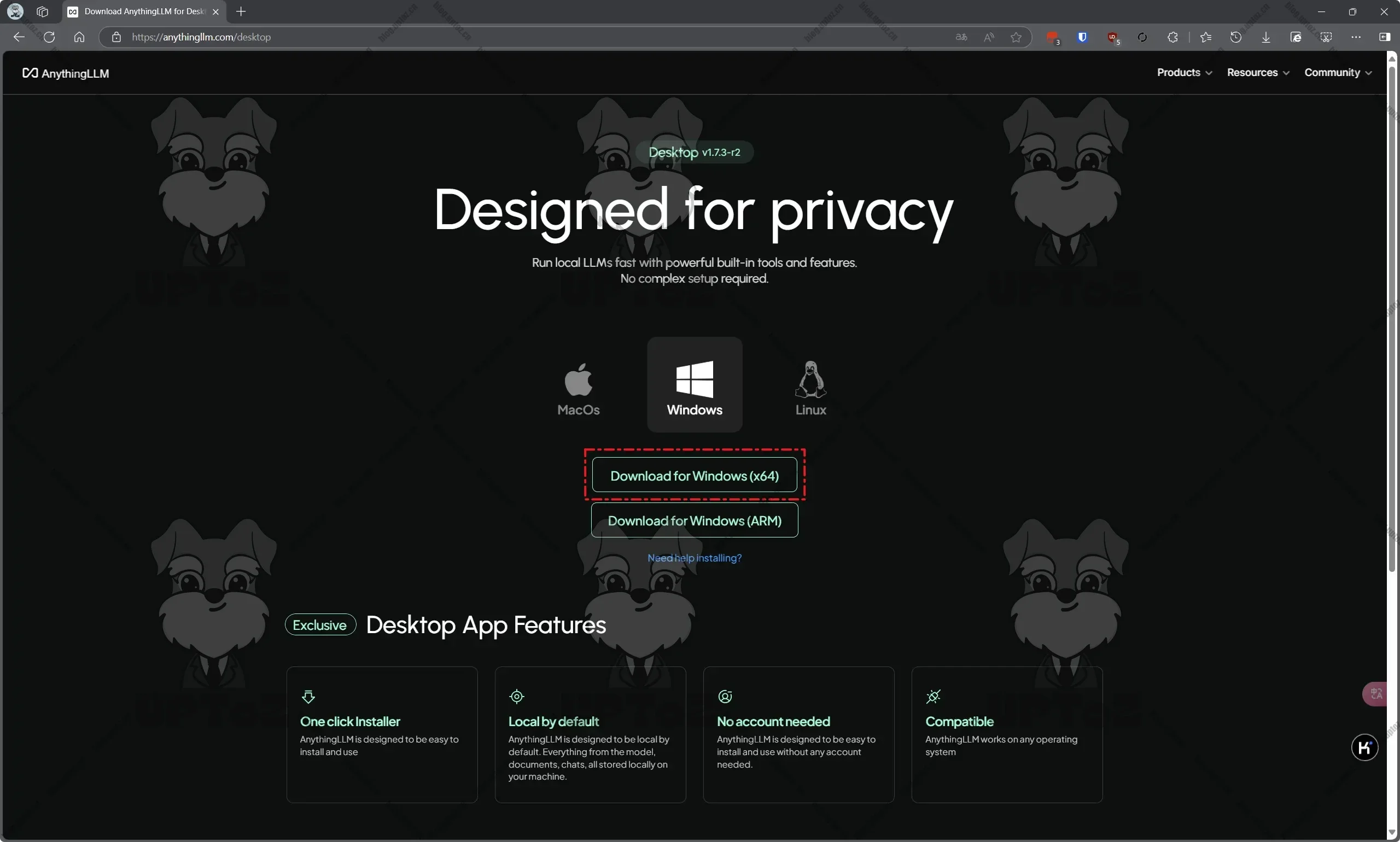
前往 AnythingLLM 官方网站(https://anythingllm.com/desktop)下载安装包。
配置LLM首选项。平台选择
Ollama,模型选择我们刚拉取的模型deepseek-r1:32b,其他保持默认,然后点击“Save changes”进行保存。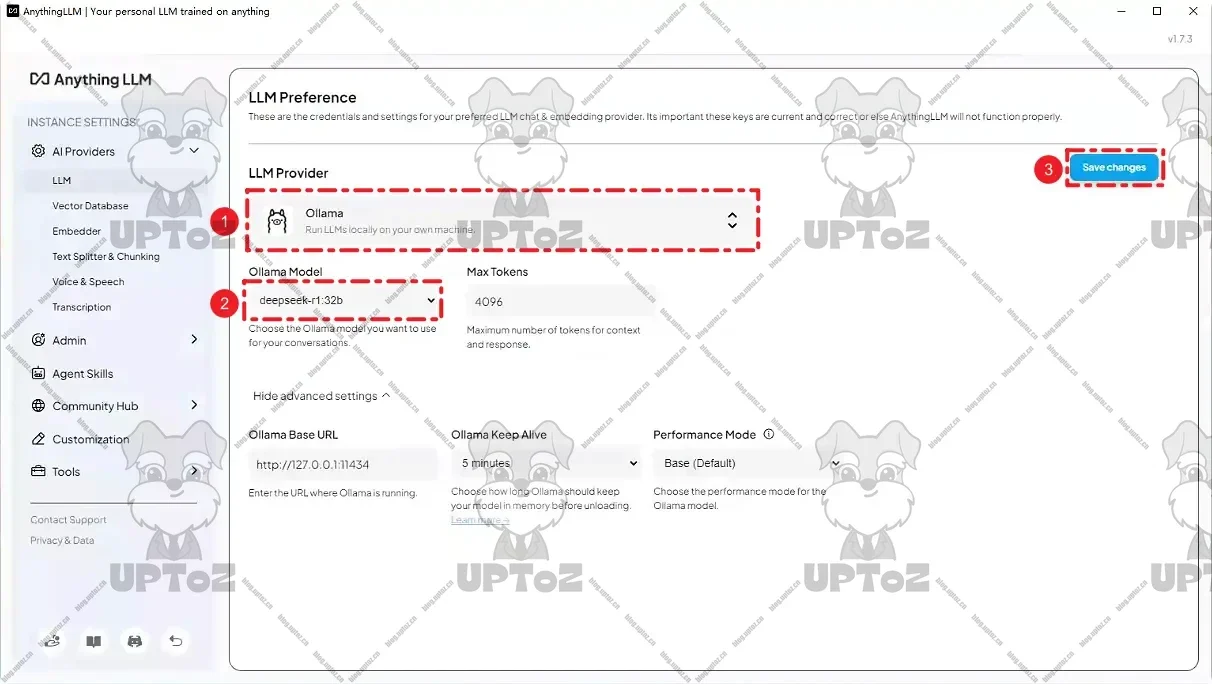
配置嵌入模型。平台选择
Ollama,模型选择nomic-embed-text:latest,其他的保持默认,然后点击“Save changes”进行保存。
如果对英文不友好,可以在 Customization 中将 Display Language 设置成
Chinese。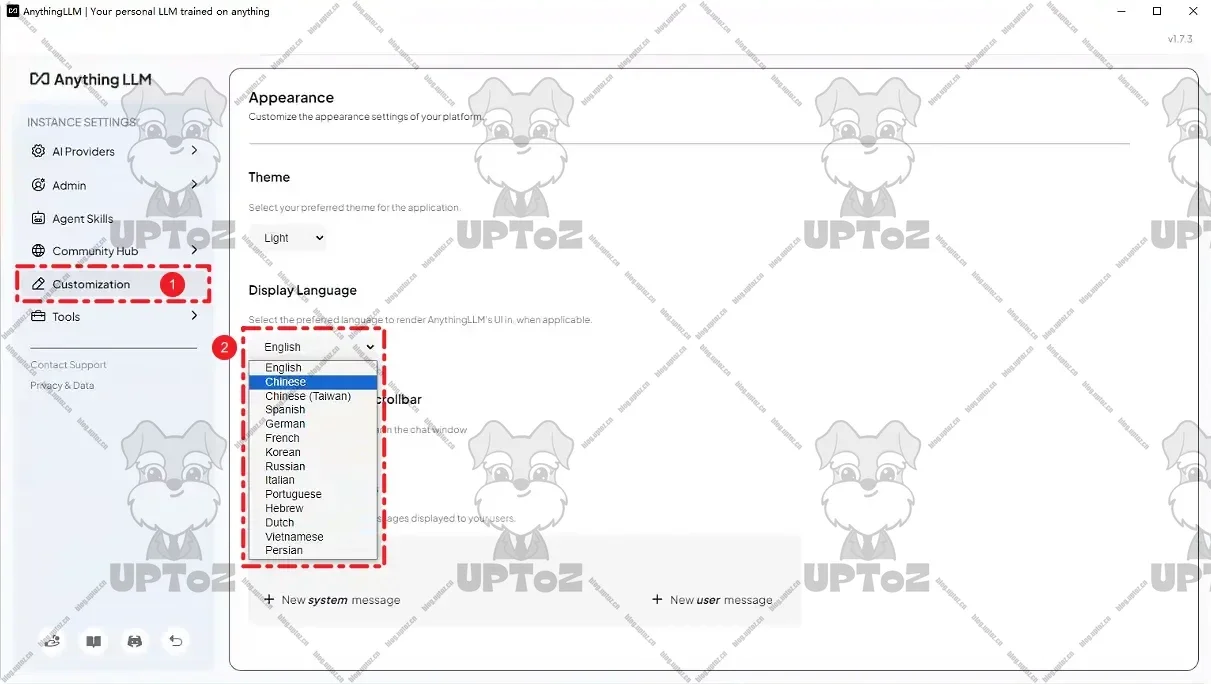
使用
创建工作区。给工作区设置一个名称,然后保存。
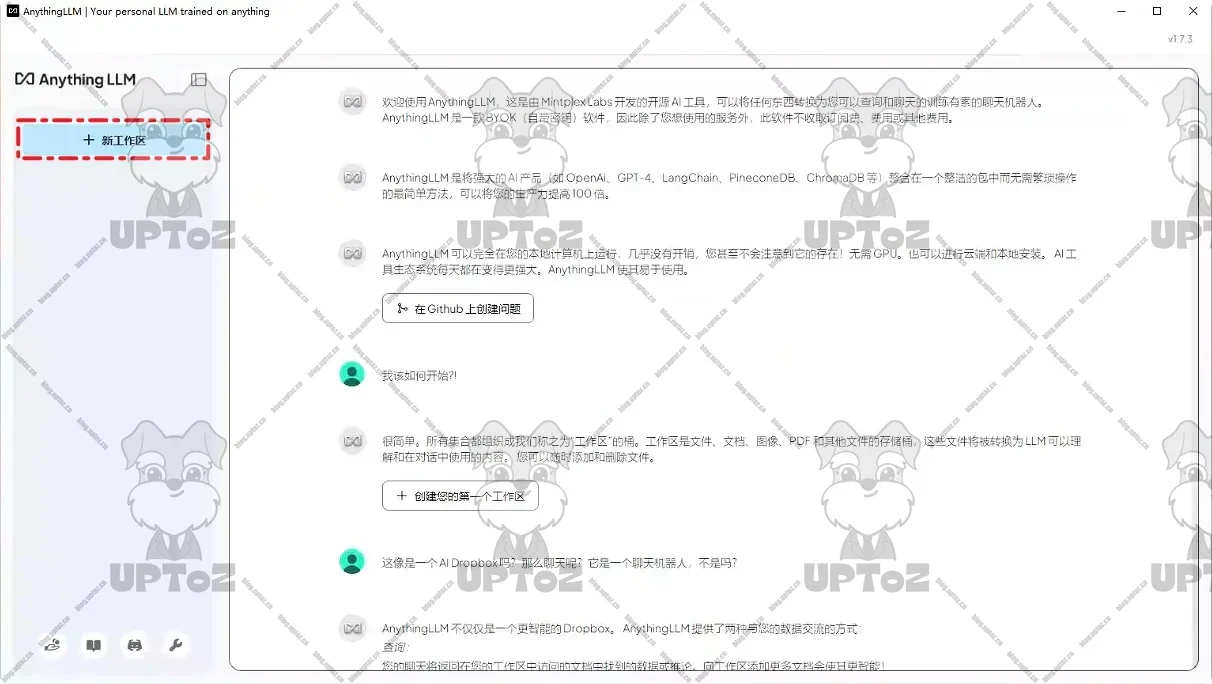
上传知识库文件。点击工作区名称旁边的上传图标,进入文件上传管理。

选择知识库文件上传。
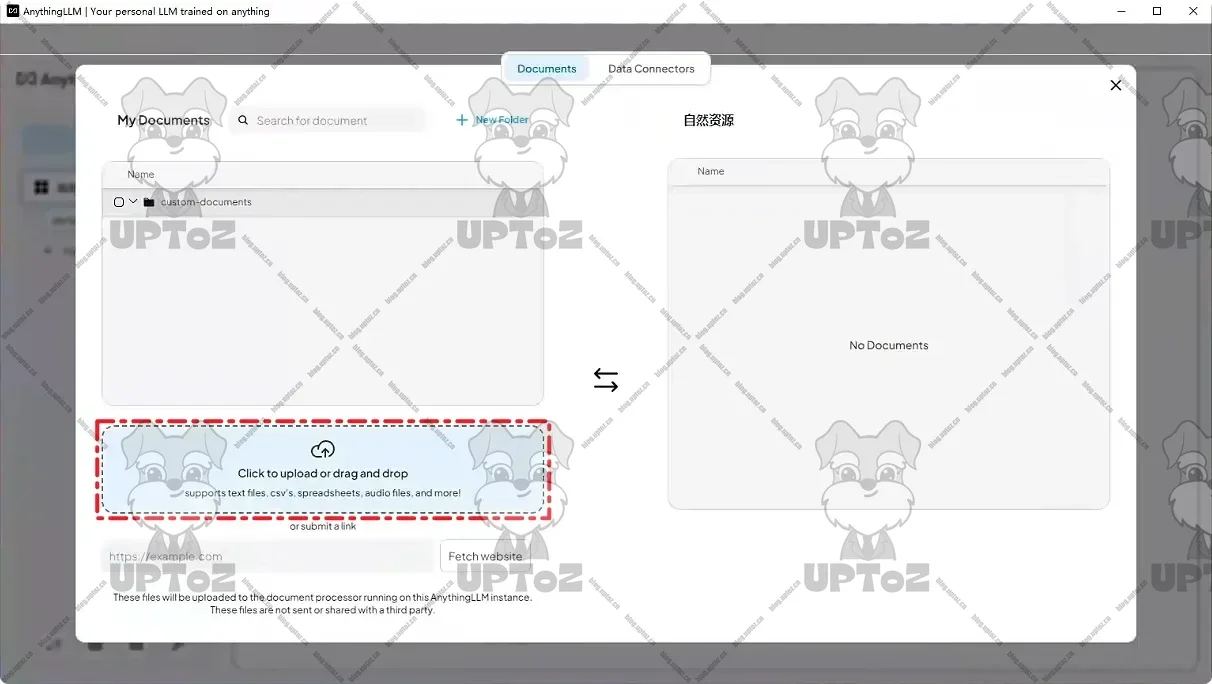
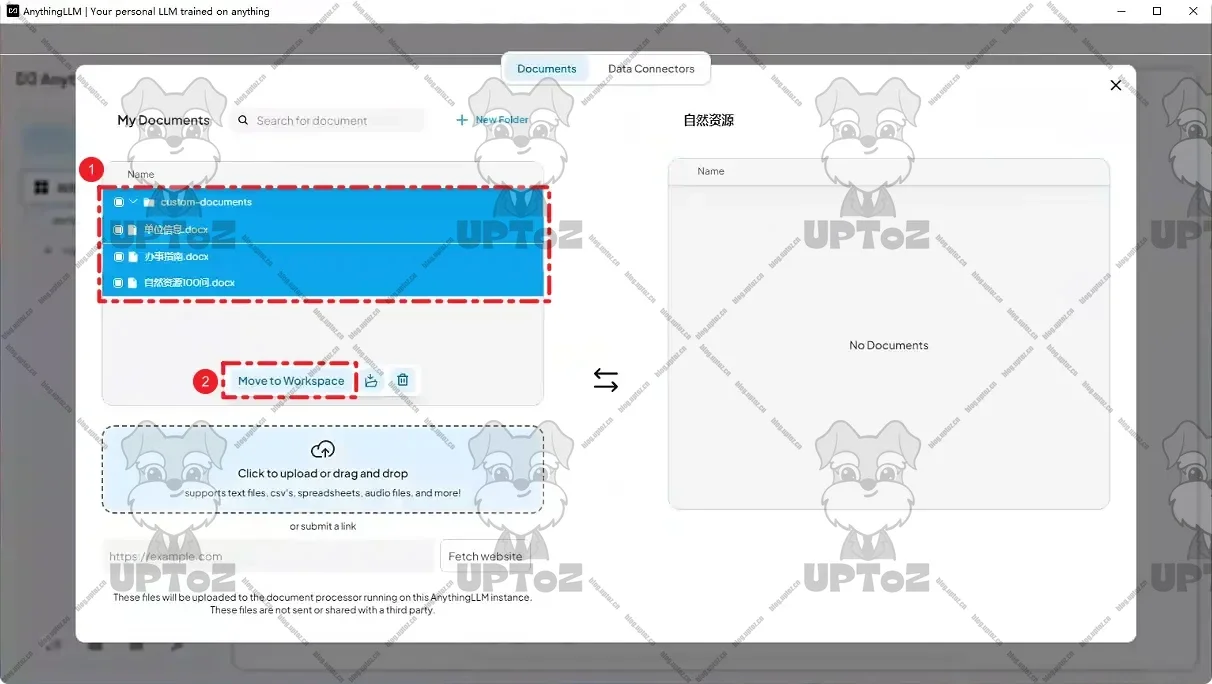
将知识库文件移动到当前工作区。
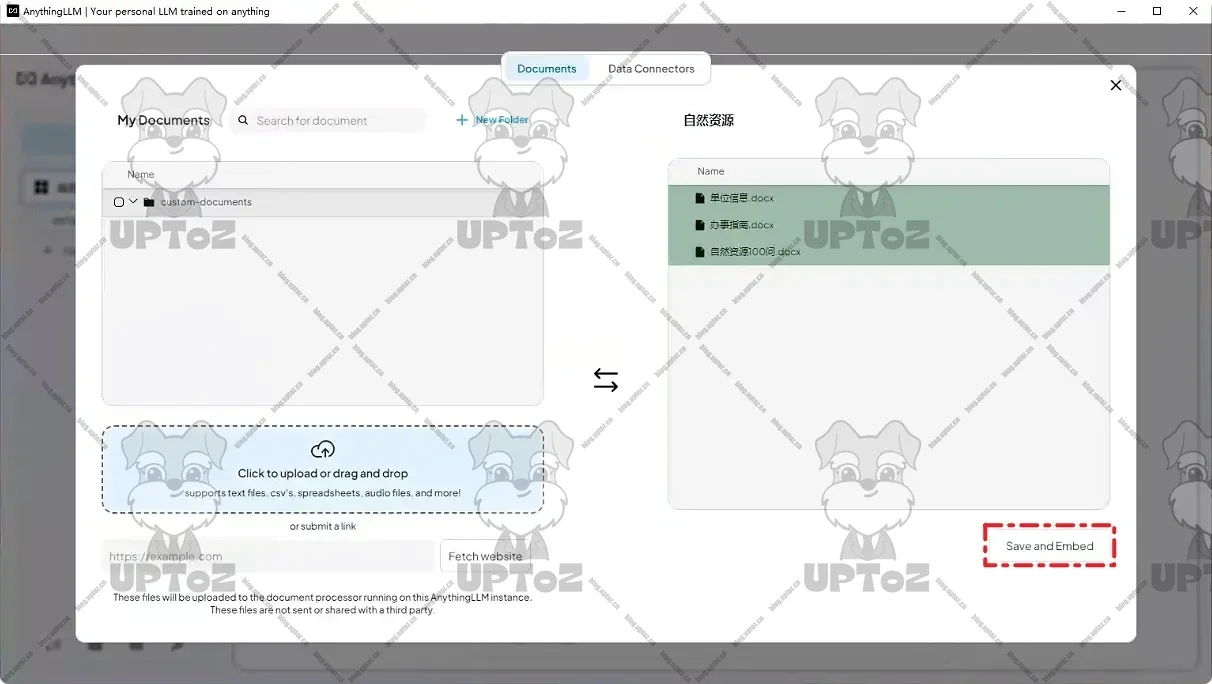
保存并嵌入知识库文件。
在工作区中与大模型进行对话。
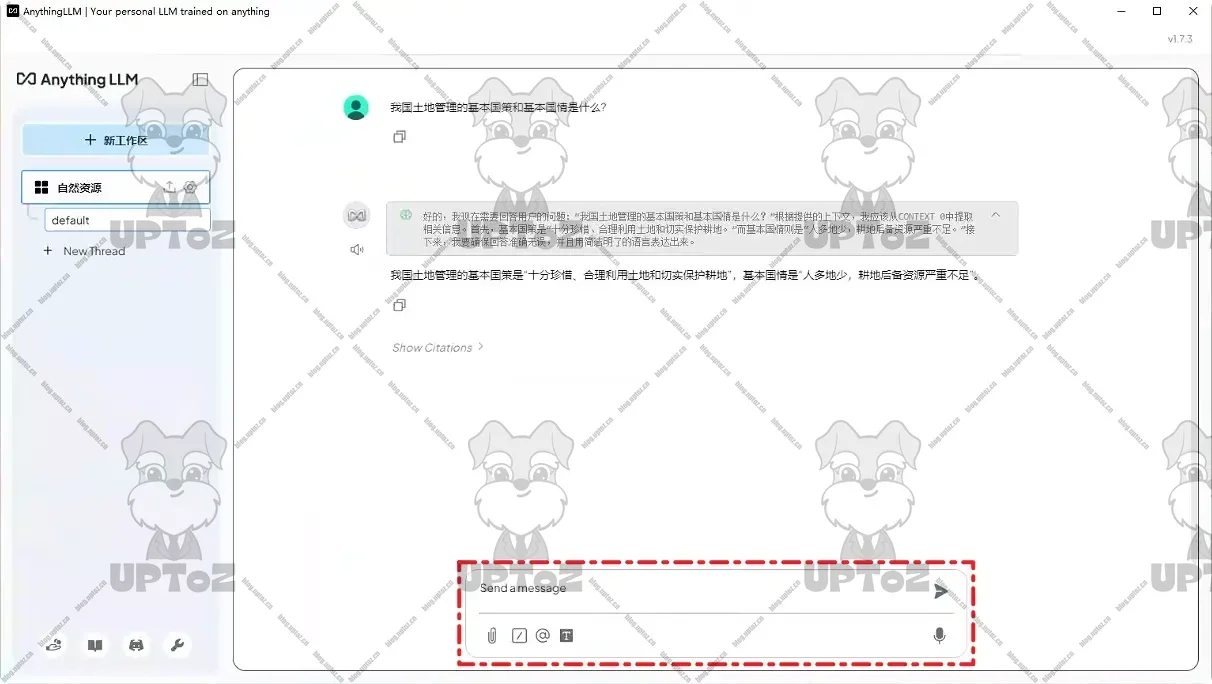
总结
在使用 DeepSeek-R1 模型的过程中,我发现当参数在 32B 及以下时,模型在处理复杂推理任务时的表现似乎不太理想,感觉有些力不从心。具体来说,它会出现中英文混合输出的情况,这在一定程度上影响了结果的准确性和可读性。
另外,就 AnythingLLM 框架而言,其检索能力也存在一些不足之处。有时候我提出的问题,明明在知识库中是存在相关知识的,但系统却提示没有找到相关知识,这说明框架的检索功能还有待进一步优化和提升,以便能更精准地定位和提供知识库中的有效信息。

- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝



