


【折腾笔记】在Linux中部署RAGFlow + Ollama
本文最后更新于 2025-09-25,文章可能存在过时内容,如有过时内容欢迎留言或者联系我进行反馈。
前言
本教程基于Ubuntu Server 24.04.2系统进行部署演示,需要提前安装好Docker和Docker Compose,如果尚未安装Docker,请参阅Install | Docker Docs(https://docs.docker.com/engine/install/)。
简介
Ollama
Ollama 是一个开源的本地大语言模型运行框架。
基本概念
核心功能:Ollama 专注于在本地机器上便捷部署和运行大型语言模型(LLM),支持多种操作系统,包括 macOS、Windows、Linux 以及通过 Docker 容器运行。
主要特点:它提供对模型量化的支持,可以显著降低显存要求,使得在普通家用计算机上运行大型模型成为可能。
主要特点
多种预训练语言模型支持:Ollama 提供了多种开箱即用的预训练模型,包括常见的 GPT、BERT 等大型语言模型,用户可以轻松加载并使用这些模型进行文本生成、情感分析、问答等任务。
易于集成和使用:Ollama 提供了命令行工具(CLI)和 Python SDK,简化了与其他项目和服务的集成,开发者无需担心复杂的依赖或配置,可以快速将 Ollama 集成到现有的应用中。
本地部署与离线使用:Ollama 允许开发者在本地计算环境中运行模型,这意味着可以脱离对外部服务器的依赖,保证数据隐私,并且对于高并发的请求,离线部署能提供更低的延迟和更高的可控性。
支持模型微调与自定义:用户不仅可以使用 Ollama 提供的预训练模型,还可以在此基础上进行模型微调,根据自己的特定需求,开发者可以使用自己收集的数据对模型进行再训练,从而优化模型的性能和准确度。
性能优化:Ollama 关注性能,提供了高效的推理机制,支持批量处理,能够有效管理内存和计算资源,这让它在处理大规模数据时依然保持高效。
跨平台支持:Ollama 支持在多个操作系统上运行,包括 Windows、macOS 和 Linux,这样无论是开发者在本地环境调试,还是企业在生产环境部署,都能得到一致的体验。
开放源码与社区支持:Ollama 是一个开源项目,这意味着开发者可以查看源代码,进行修改和优化,也可以参与到项目的贡献中,此外,Ollama 有一个活跃的社区,开发者可以从中获取帮助并与其他人交流经验。
功能
本地模型管理:Ollama 支持从官方模型库或自定义模型库拉取预训练模型,并在本地保存和加载,它支持各种流行的模型格式(如 ONNX、PyTorch、TensorFlow)。
高效推理:通过 GPU/CPU 的加速,Ollama 提供高效的模型推理,适合本地化应用或需要控制数据隐私的场景。
多种接口访问:Ollama 支持命令行(CLI)、HTTP 接口访问推理服务,并通过 OpenAI 客户端实现更广泛的集成。
环境变量配置:通过灵活的环境变量,用户可以自定义推理设备(GPU/CPU)、缓存路径、并发数、日志级别等。
RAGFlow
RAGFlow 是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。
核心功能与优势
高质量的文档提取:支持多种格式的文档,能确保准确地抽取信息,可处理 Word、幻灯片、Excel、文本、图像、扫描件、结构化数据、网页等多种数据源。
基于模板的切片模式:支持各类切片模式,可根据不同场景的需求灵活地对数据进行分割。
检索内容可视化与溯源:检索内容支持溯源,切片透明,提高了系统的可解释性和可信度,能减少模型幻觉,提供有根据的引用。
多数据源与模型对接:支持多种类型的数据源,适应各种数据环境,提高了系统的通用性;同时兼容不同的语言模型,满足多样化的应用需求。
提供便捷 API:便于集成到现有系统中,能有效提高开发效率。
多路召回与重排序:通过多路召回和融合重排序,提高了检索精度和相关性。
支持 Graph 定制工作流:可以实现复杂的智能交互和决策流程。
工作原理
首先对文档进行摄取和预处理,接着生成嵌入向量,然后对用户查询进行编码,再检索相关文档,构建增强提示,最后生成响应并进行验证和处理。
应用场景
在客户服务、问答系统、智能搜索、内容推荐等领域都有重要应用,例如在在线客服系统中,能利用用户的历史咨询记录、产品文档以及 FAQ 等数据,实时检索出关联度最高的信息,并生成自然、连贯的应答,提升客户满意度。
系统架构
主要包含数据检索模块和生成模块。数据检索模块负责在海量数据中快速定位、收集与过滤结果信息;生成模块则基于检索结果,利用生成式模型生成高质量的应答或文本内容。
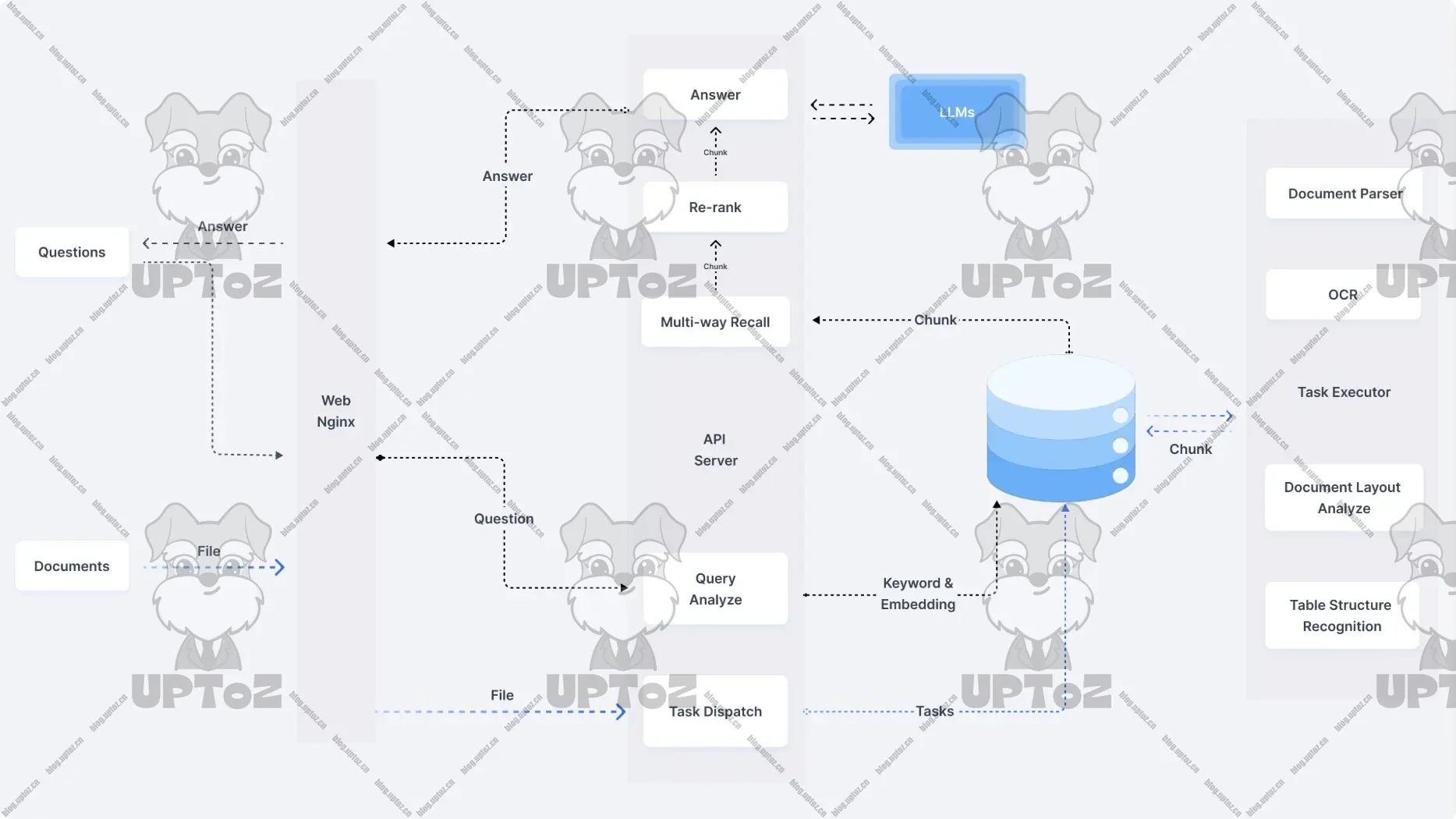
部署
Ollama
通过官方提供的命令进行安装。
curl -fsSL https://ollama.com/install.sh | sh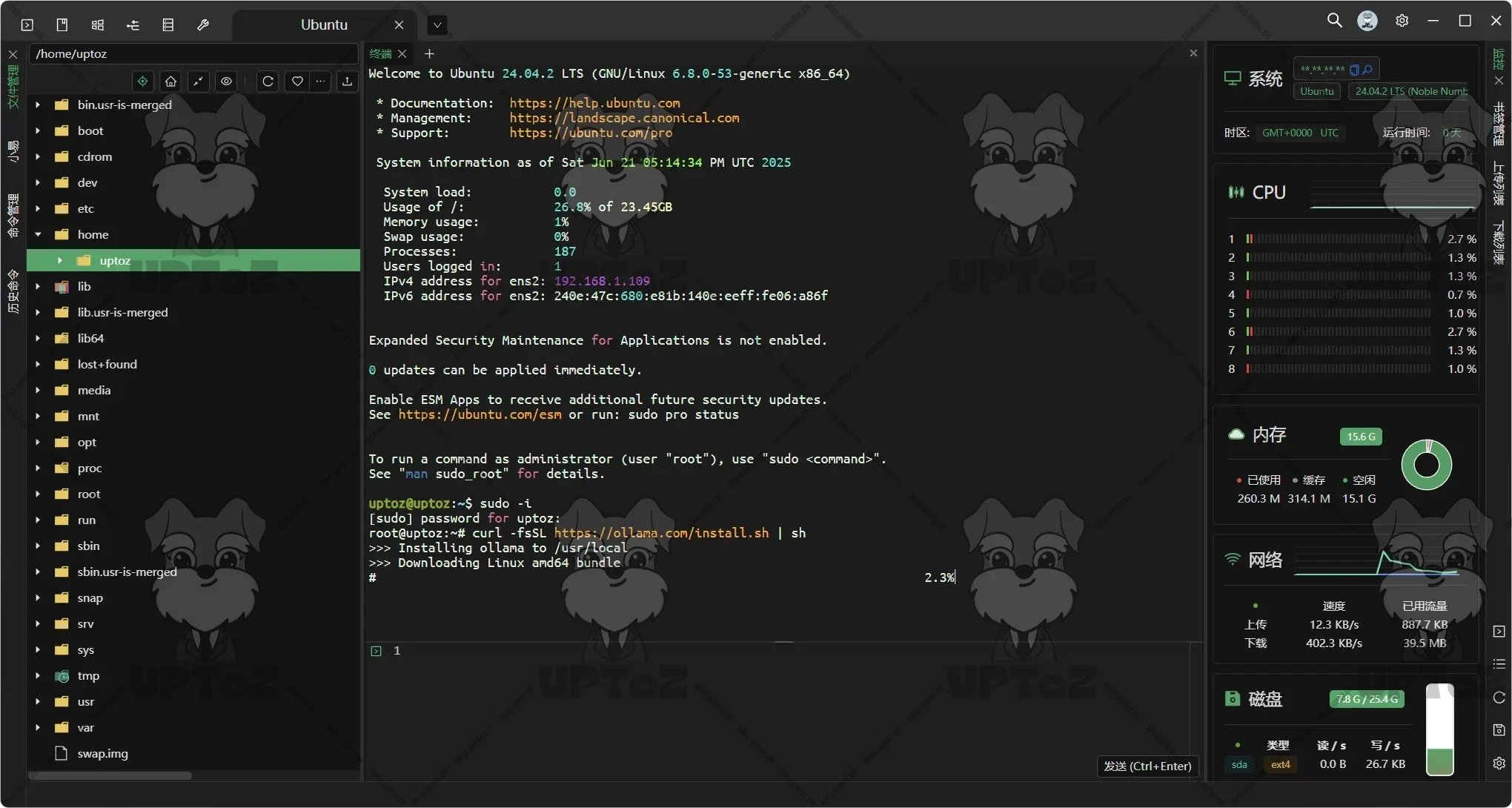
通过
ollama --version检查ollama是否成功安装。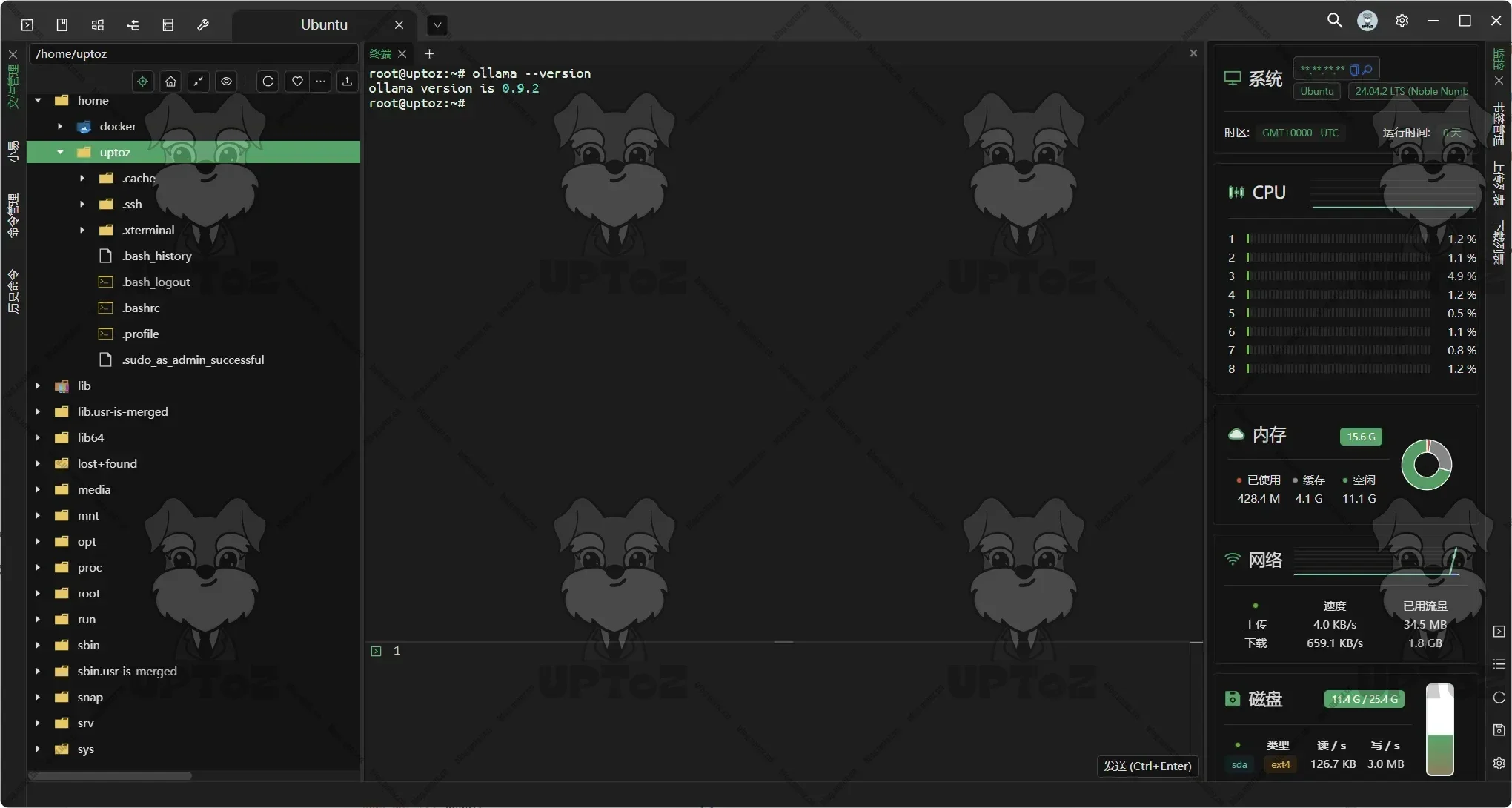
在Ollama Model (https://ollama.com/search)中查看支持的模型,通过
ollama pull命令下载模型到本地。# 拉取 qwen3:8b ollama pull qwen3:8b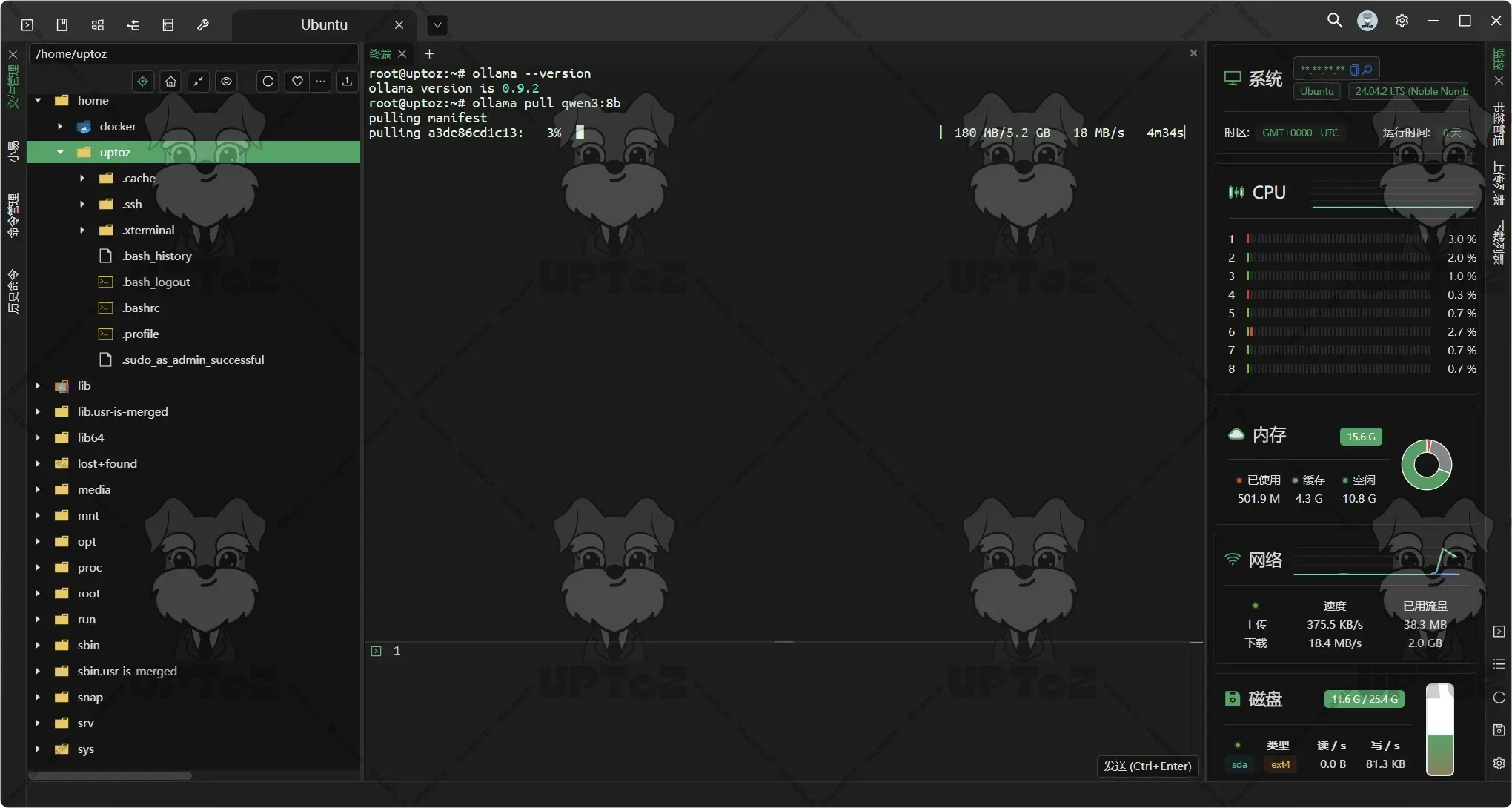
(可选)Ollama默认监听
127.0.0.1的接口,可通过systemd 服务配置来修改Ollama默认监听IP。sudo nano /etc/systemd/system/ollama.service增加以下配置,监听所有接口0.0.0.0可能暴露服务到公网,建议结合防火墙使用。
Environment="OLLAMA_HOST=0.0.0.0" Environment="OLLAMA_ORIGINS=*"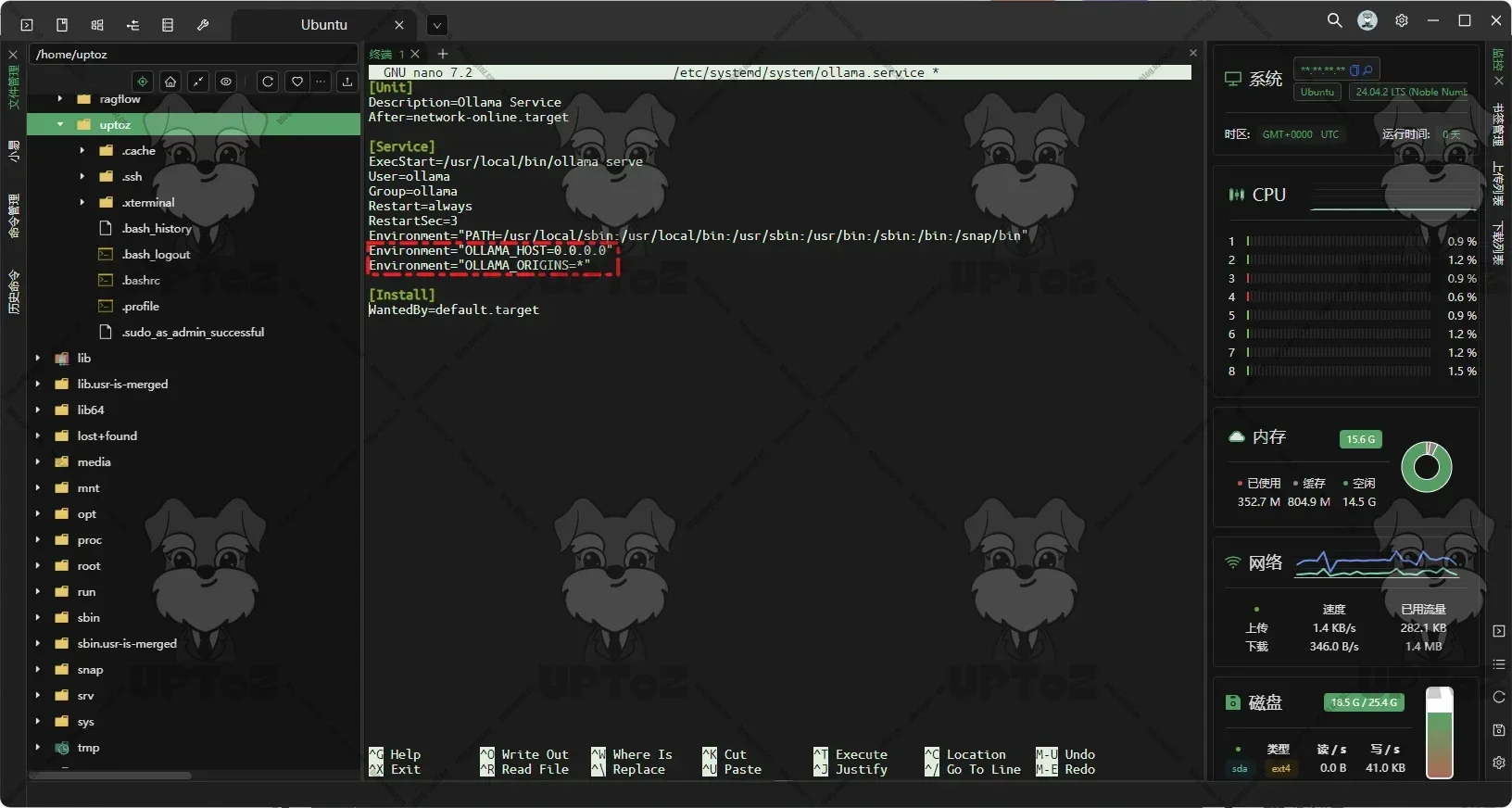
CTRL + O写入文件,然后回车,最后CTRL + X 离开。最后重新加载配置并重启服务:
sudo systemctl daemon-reload sudo systemctl restart ollama
RAGFlow
README(https://github.com/infiniflow/ragflow/blob/main/docker/README.md)
克隆仓库。
git clone https://github.com/infiniflow/ragflow.git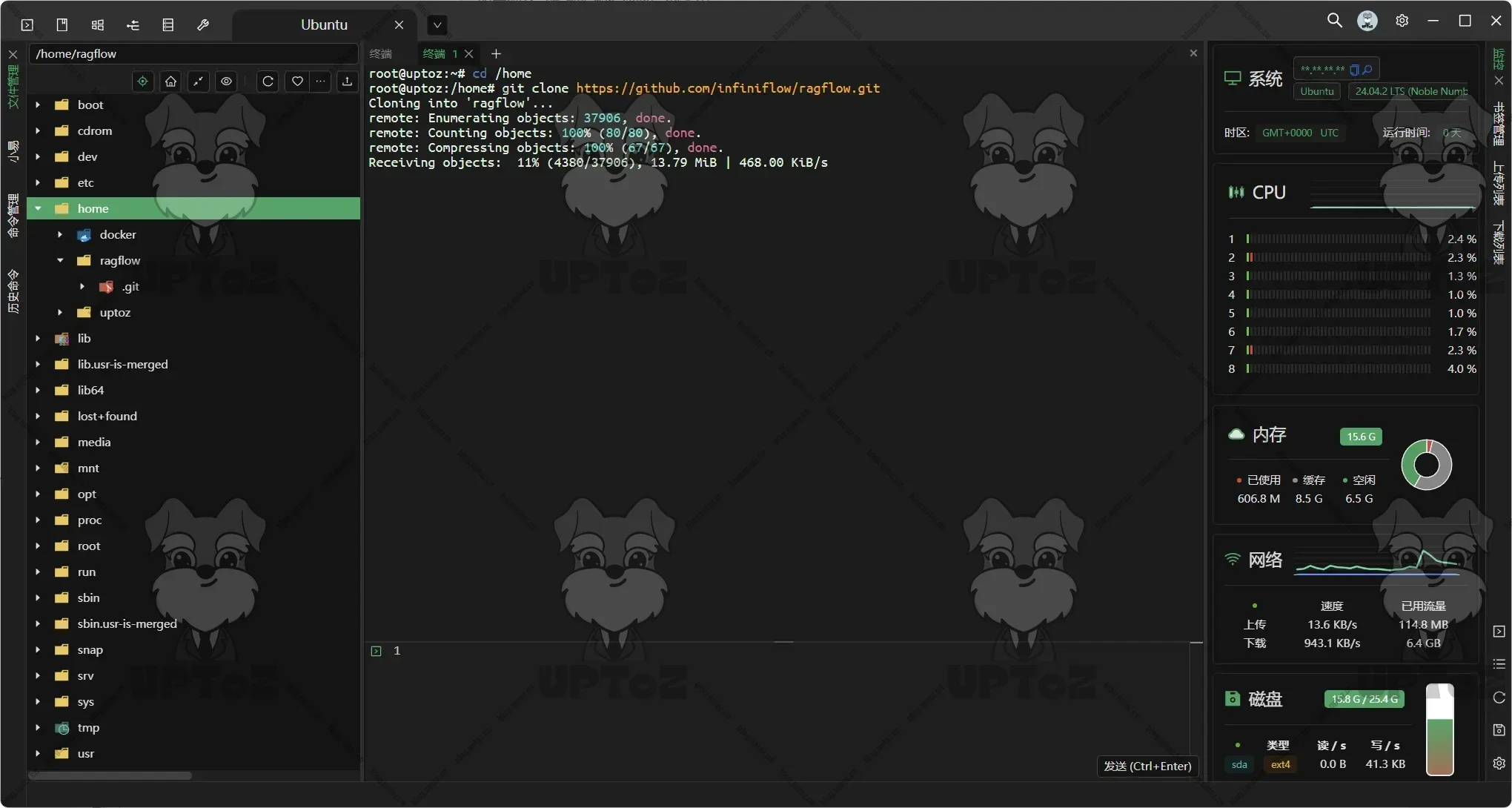
通过
cd命令进入到 docker 文件夹。cd ragflow/docker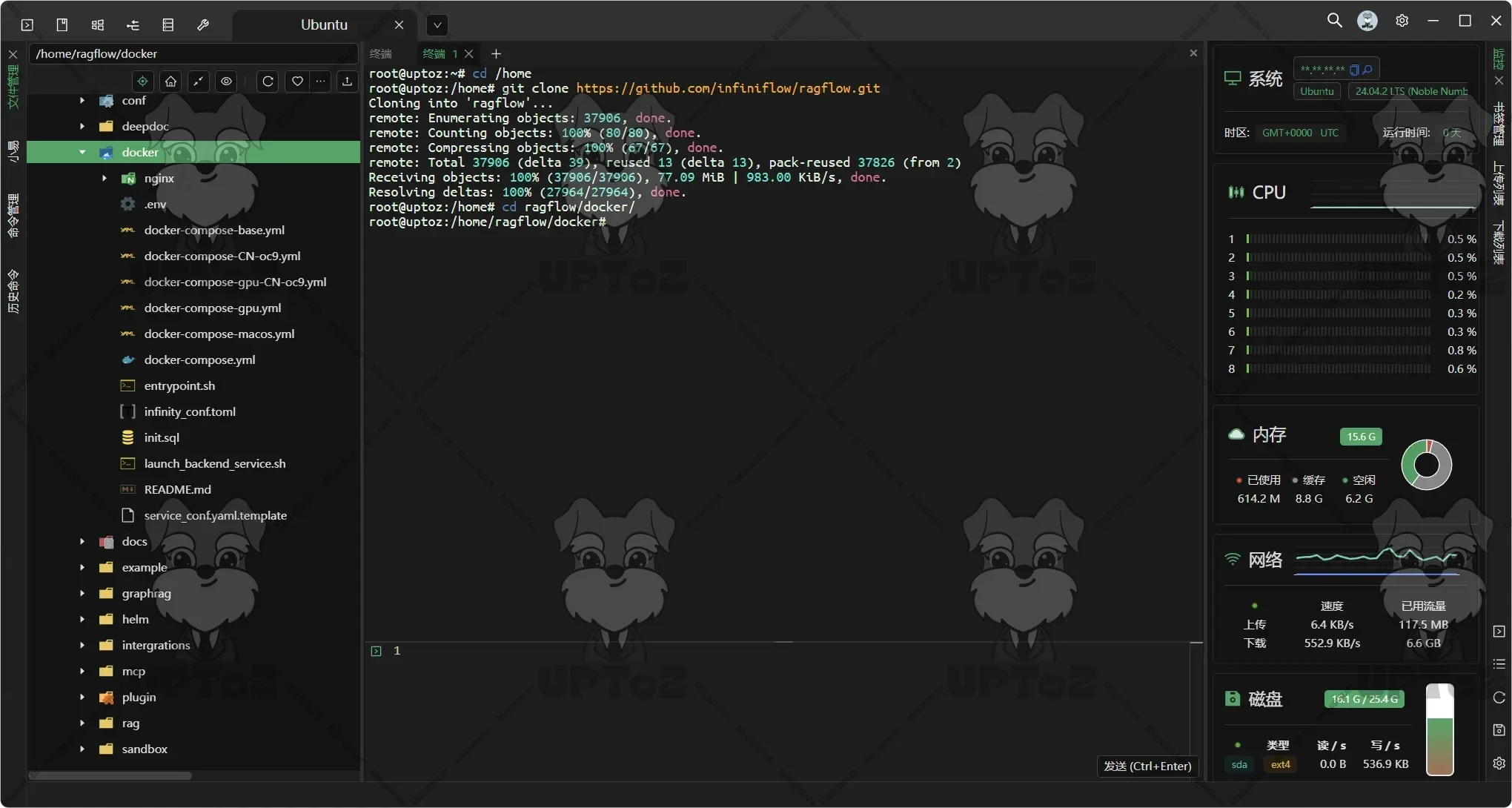
更新 docker/.env 文件内的
RAGFLOW_IMAGE变量,设置RAGFLOW_IMAGE=infiniflow/ragflow:v0.19.1来下载 RAGFlow 镜像的 v0.19.1 完整发行版。vim .env按
i键进入编辑模式,修改好上述的环境变量后,按esc键退出编辑模式,随后输入:wq表示写入并退出。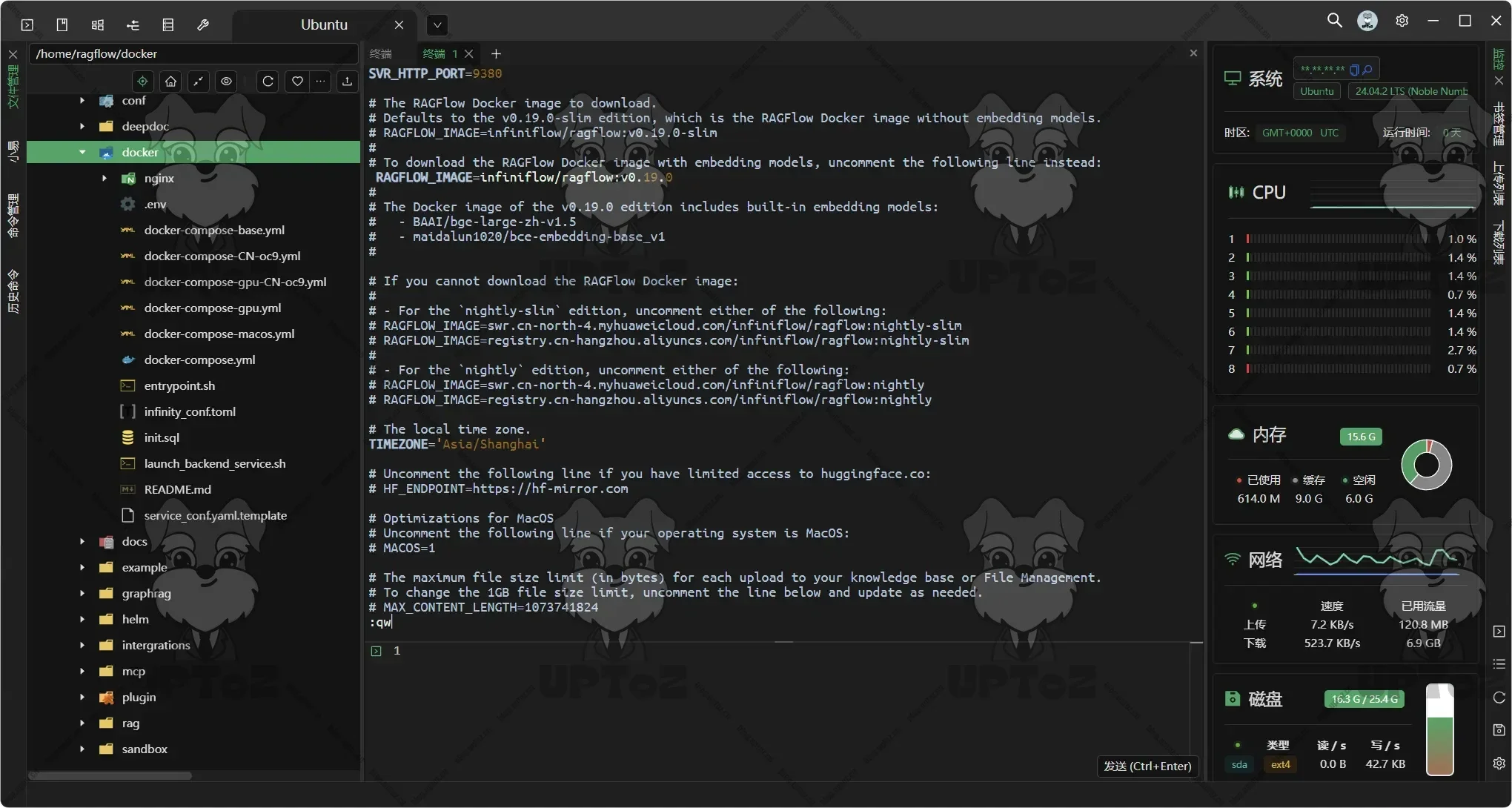
(可选)修改RAGFlow服务默认端口
默认HTTP是
80端口HPPTS是443端口。vim docker-compose.yml按
i键进入编辑模式,将宿主机的映射端口进行修改,按esc键退出编辑模式,随后输入:wq表示写入并退出。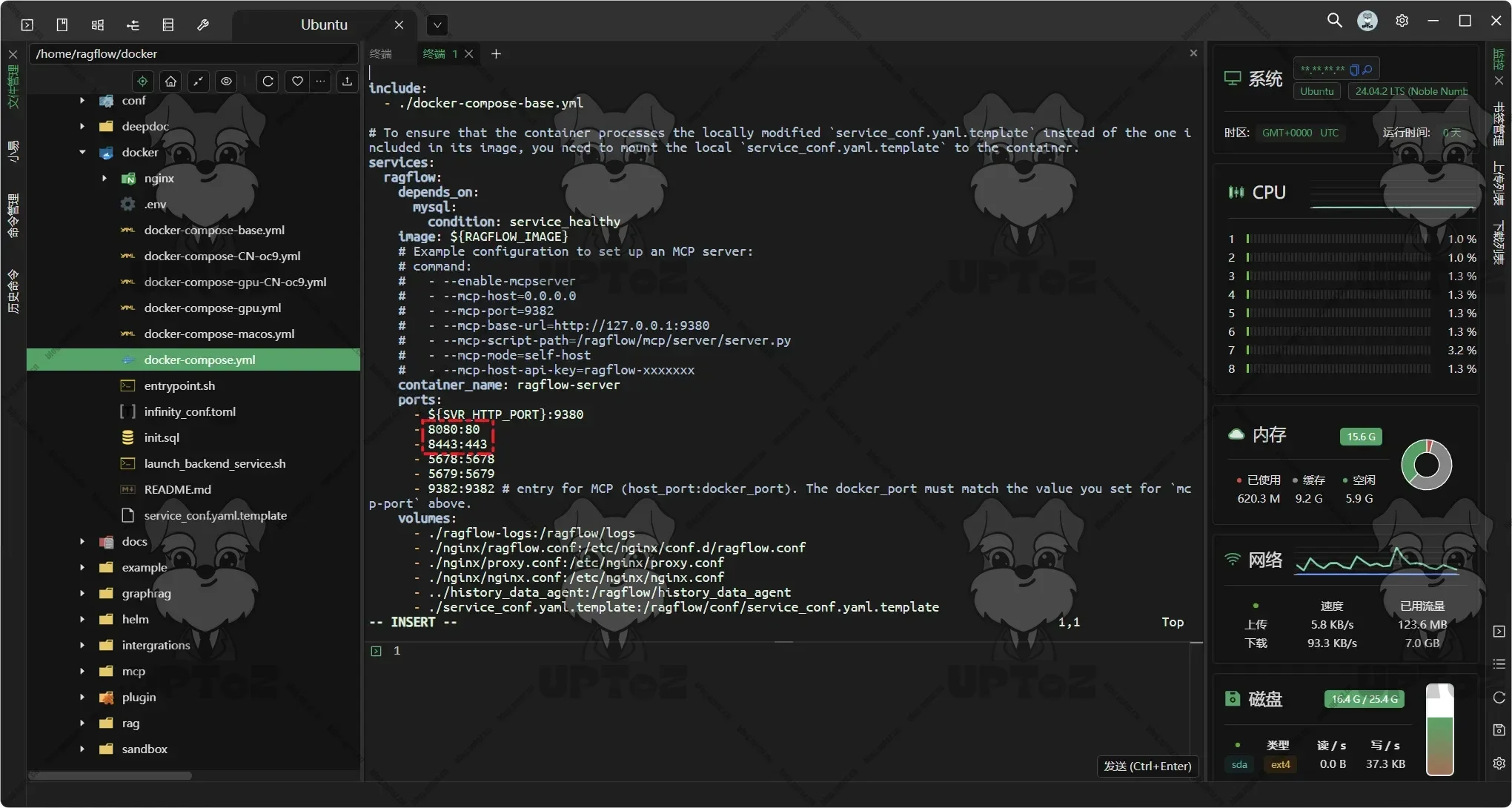
使用docker compose命令运行。
docker compose -f docker-compose.yml up -d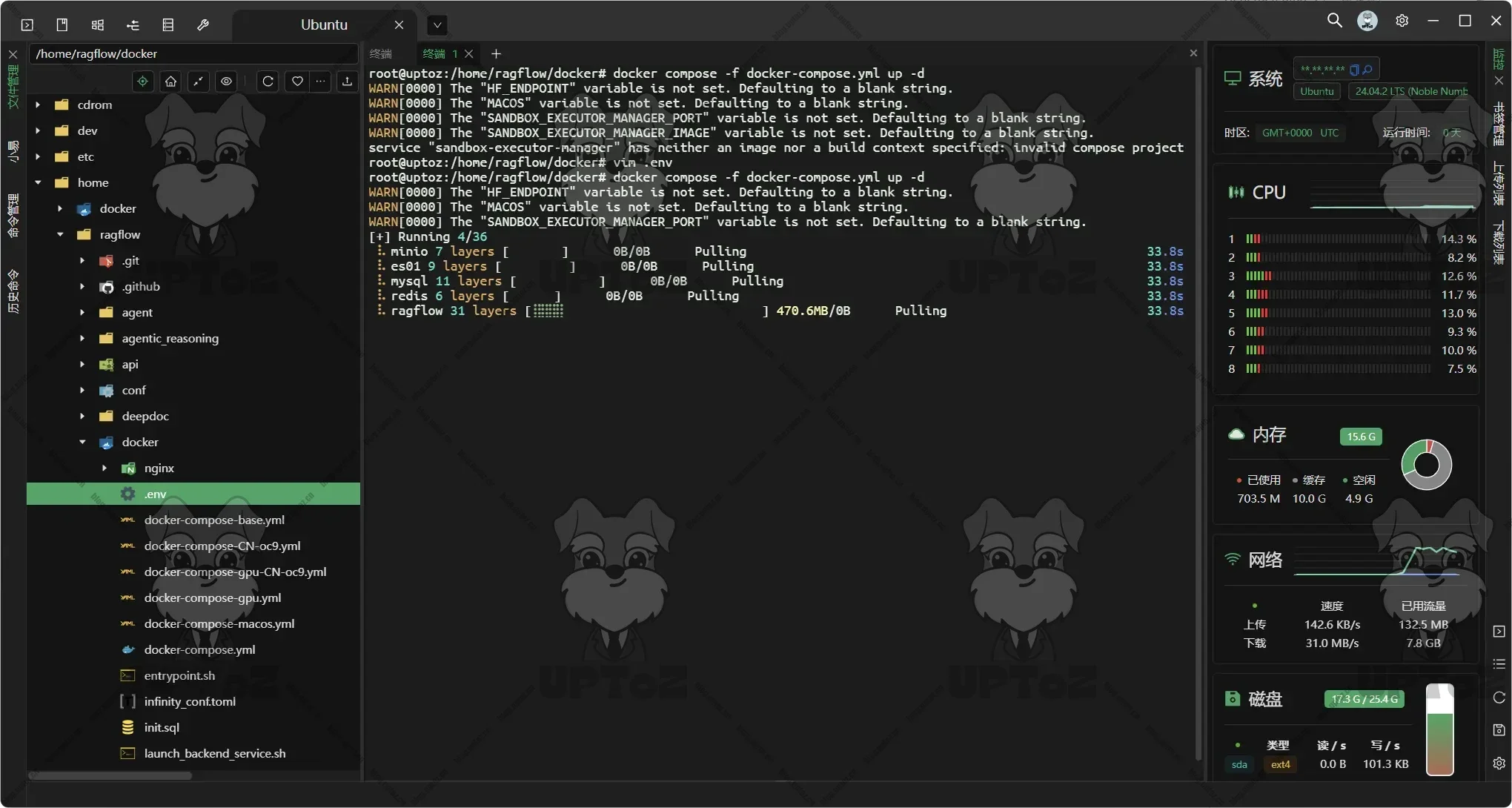
启动并运行服务器后,检查服务器状态。
docker logs -f ragflow-server以下输出确认系统成功启动
____ ___ ______ ______ __ / __ \ / | / ____// ____// /____ _ __ / /_/ // /| | / / __ / /_ / // __ \| | /| / / / _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ / /_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/ * Running on all addresses (0.0.0.0)

- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝



