

















【Docker】搭建一款高性能、开源、无表结构的文档型数据库 - MongoDB
本文最后更新于 2025-08-11,文章可能存在过时内容,如有过时内容欢迎留言或者联系我进行反馈。
前言
本教程基于飞牛系统 fnOS 0.9.15 的 Docker Compose 功能进行搭建。
简介
MongoDB 是一款高性能、开源、无 schema(模式)的文档型数据库,属于 NoSQL(非关系型数据库)的一种。它以灵活的文档模型、良好的可扩展性和强大的查询能力,广泛应用于各类互联网应用、大数据场景和敏捷开发项目中。
特点
文档模型(Document Model)
数据以 BSON(Binary JSON)格式存储,类似 JSON 文档,支持嵌套结构和数组,能自然映射对象模型(如编程语言中的类和对象)。
示例文档:
{ "_id": ObjectId("60d21b4667d0d8992e610c85"), "name": "MongoDB", "type": "database", "features": ["document-oriented", "schema-less", "high performance"], "version": 6.0, "metadata": { "releaseDate": "2022-07-12", "license": "SSPL" } }无需预定义表结构(schema),字段可动态添加,适合需求频繁变化的场景。
高性能
支持内存映射存储,频繁访问的数据可缓存在内存中,读写速度快。
索引机制丰富,支持单字段索引、复合索引、地理空间索引、文本索引等,优化查询效率。
高可用性与容错
通过 副本集(Replica Set) 实现高可用:由主节点(Primary)、从节点(Secondary)和仲裁节点(Arbiter)组成,主节点故障时自动选举新主节点,确保服务不中断。
数据自动同步到从节点,具备数据冗余和故障恢复能力。
水平扩展能力
支持 分片(Sharding):将数据按分片键(Shard Key)分布到多个分片集群,突破单节点存储和性能瓶颈,可线性扩展。
丰富的查询与聚合功能
支持复杂查询(如范围查询、正则匹配、嵌套文档查询)、更新和删除操作。
提供 聚合管道(Aggregation Pipeline),可实现数据过滤、分组、排序、计算等复杂数据分析,类似 SQL 中的
GROUP BY和JOIN。
MongoDB 与关系型数据库的对比
适用场景
灵活的数据结构:如内容管理系统(CMS)、博客平台,字段频繁变更无需修改表结构。
高并发读写:如电商商品信息、用户行为日志,支持快速插入和查询。
大数据存储与分析:结合分片和聚合管道,处理海量数据(如物联网传感器数据、日志分析)。
敏捷开发:迭代速度快,无需前期严格设计 schema,加速开发周期。
部署
打开Docker管理器,选择「Compose」,点击右上角「新增项目」。

在创建项目窗口中填写「项目名称」和选择数据存放「路径」,然后选择「创建docker-compose.yml」,将下列代码根据自己实际情况修改后复制粘贴进去。
version: '3.8' services: mongodb: image: mongo:6.0 container_name: mongodb restart: always ports: - "27017:27017" volumes: - ./data/db:/data/db # 数据持久化 environment: MONGO_INITDB_ROOT_USERNAME: root MONGO_INITDB_ROOT_PASSWORD: p@ssw0rd勾选「创建项目后立即启动」,最后点击「确定」。

使用
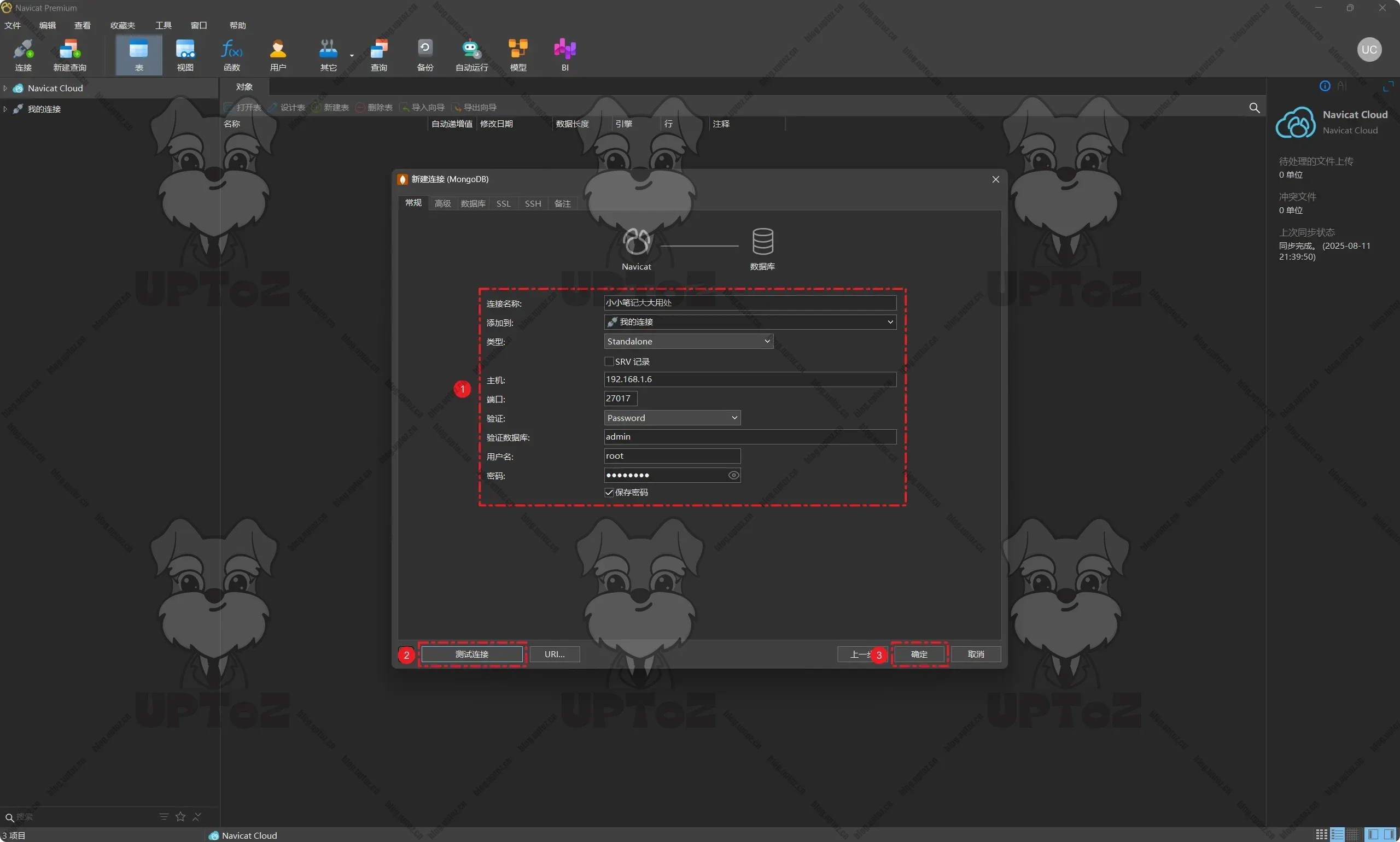
使用数据库管理工具进行连接,「连接名称」根据自己喜好进行命名,「主机」则输入自己的NAS设备的IP地址,「端口」使用你设置的端口号,「密码」则输入你设置的数据库访问密码。
此处演示使用的是“Navicat”数据库管理工具,也可以选择其他数据库管理工具,比如MongoDB Compass、Robo 3T等。

- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝



